Wrapper 包装法
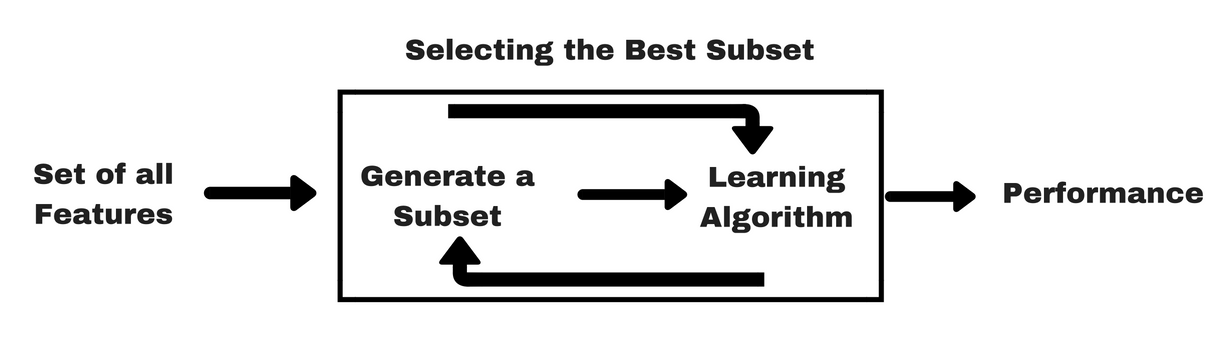
包装类方法使用预测模型给特征子集打分。每个新子集都被用来训练一个模型,然后用验证数据集来测试。通过计算验证数据集上的错误次数(即模型的错误率)给特征子集评分。由于包装类方法为每个特征子集训练一个新模型,所以计算量很大。不过,这类方法往往能为特定类型的模型找到性能最好的特征集。
前向选择法
这是一种基于循环的方法,开始时我们训练一个不包含任何特征的模型,而后的每一次循环我们都持续放入能最大限度提升模型的变量,直到任何变量都不能提升模型表现。
后向剔除法
该方法先用所有特征建模,再逐步剔除最不显著的特征来提升模型表现。同样重复该方法直至模型表现收敛。
递归特征消除法(RFE)
这是一种搜索最优特征子集的贪心优化算法,它会反复地训练模型并剔除每次循环的最优或最劣特征。下一次循环,则使用剩余的特征建模直到所有特征都被剔除。之后,按照剔除的顺序给所有特征排序作为特征重要性的度量。
对于一个为数据特征指定权重的预测模型(例如,线性模型对应参数coefficients),递归特征消除通过递归减少考察的特征集规模来选择特征。首先,预测模型在原始特征上训练,每项特征指定一个权重。之后,那些拥有最小绝对值权重的特征被踢出特征集。如此往复递归,直至剩余的特征数量达到所需的特征数量。
RFE的稳定性很大程度上取决于在迭代的时候底层用哪种模型。例如,假如RFE采用的普通的回归,没有经过正则化的回归是不稳定的,那么RFE就是不稳定的;假如采用的是Ridge,而用Ridge正则化的回归是稳定的,那么RFE就是稳定的。
以下是利用递归特征消除的例子,使用feature_selection库的RFE类结合SVM模型,在Friedman1数据集(由sklearn提供)上选择5个最相关的特征。
>>> from sklearn.datasets import make_friedman1
>>> from sklearn.feature_selection import RFE
>>> from sklearn.svm import SVR
#sklearn的friedman1数据集
>>> X, y = make_friedman1(n_samples=50, n_features=10, random_state=0)
#estimator为用于训练原始特征的预测模型,此处选择支持向量机SVR
>>> estimator = SVR(kernel="linear")
#RFE参数为:预测模型、选择的特征数、每轮迭代淘汰的特征数量
>>> selector = RFE(estimator, n_features_to_select = 5, step=1)
>>> selector = selector.fit(X, y)
#返回选取特征的结果
>>> selector.support_
array([ True, True, True, True, True,
False, False, False, False, False], dtype=bool)
#特征排名,所有被选上的特征都是rank1
>>> selector.ranking_
array([1, 1, 1, 1, 1, 6, 4, 3, 2, 5])
包装法的改进
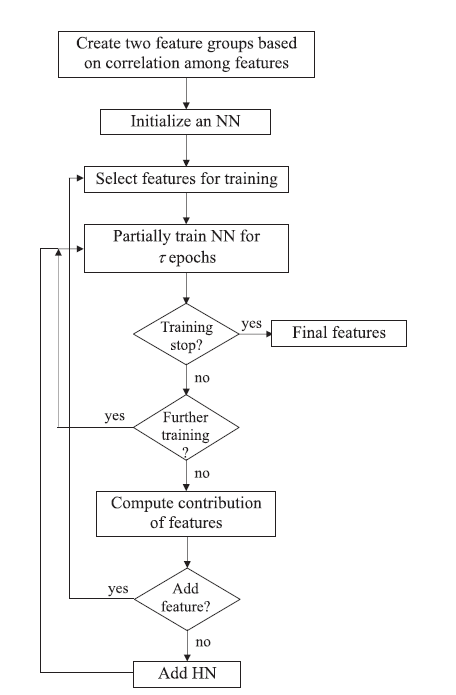
也有学者利用神经网络对传统的包装法进行改进,在“A new wrapper feature selection approach using neural network”这篇论文中,作者将初始的特征集根据特征之间的相似程度均等地分为两个子集S和D,建立一个三层的神经网络结构,并分别从S和D中选择一个与同特征子集中其他特征相似度最小的特征加入训练,通过该神经网络以及输入的特征子集进行训练,通过预测结果与实际标签的比较判定是否选择该特征,如果当前输入的特征不符合要求,则增加隐层单元数量并且选择新的特征。模型的结构图如下所示:
参考资料
- https://blog.csdn.net/qq_39303465/article/details/79221254
- https://en.wikipedia.org/wiki/Feature_selection#Filter_method
- http://sklearn.lzjqsdd.com/modules/feature_selection.html
- https://zhuanlan.zhihu.com/p/32335608
- https://ask.hellobi.com/blog/lsxxx2011/10426
- http://sofasofa.io/forum_main_post.php?postid=1000484
- https://zh.wikipedia.org/wiki/%E4%BA%92%E4%BF%A1%E6%81%AF
- https://zh.wikipedia.org/wiki/%E7%86%B5_(%E4%BF%A1%E6%81%AF%E8%AE%BA))
- https://www.deeplearn.me/1466.html
- https://blog.csdn.net/u014271612/article/details/51781250
- http://nbviewer.jupyter.org/github/jaganadhg/data_science_notebooks/blob/master/sklearn/scikit_learn_feature_selection.ipynb
- http://featureselection.asu.edu/tutorial.php
- https://www.cnblogs.com/stevenlk/p/6543628.html
- https://blog.csdn.net/u012328159/article/details/53954522
- https://blog.csdn.net/jetFlow/article/details/78884619
- http://www.ituring.com.cn/article/273668
- https://www.zhihu.com/question/28641663
- http://www.cnblogs.com/stevenlk/p/6543646.html
- https://www.cnblogs.com/stevenlk/p/6543628.html
- http://www.cnblogs.com/ooon/p/5677098.html
- https://blog.csdn.net/drbinzhao/article/details/52930600