特征组合
通过将单独的特征进行组合(求内积或求笛卡尔积)而形成的合成特征。特征组合有助于表示非线性关系。
GBDT
主要思想:利用已有的特征训练GBDT模型,然后利用GBDT模型学习到的树来构造新特征,然后把这些新特征加入原有特征一起训练模型。构造的新特征向量取值是0/1,向量的每个元素对应于GBDT模型中的树的叶子结点。当一个样本点通过某棵树最终落在这棵树的一个叶子结点上,那么在新特征向量中这个叶子结点对应的元素值为1,而这棵树的其他叶子结点对应的元素值为0。新特征向量的长度等于GBDT模型里所有数包含的叶子结点数之和。
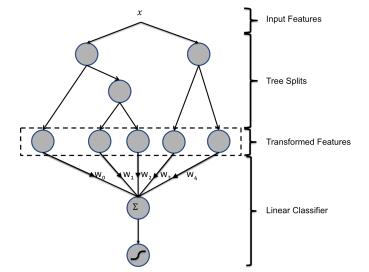
例:上图有两棵树,左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第一个节点,编码[1,0,0],落在右树第二个节点则编码[0,1],所以整体的编码为[1,0,0,0,1],这类编码作为特征,输入到线性分类模型(LR or FM)中进行分类。
# 弱分类器的数目
n_estimator = 10
# 随机生成分类数据。
X, y = make_classification(n_samples=80000)
# 切分为测试集和训练集,比例0.5
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
# 将训练集切分为两部分,一部分用于训练GBDT模型,另一部分输入到训练好的GBDT模型生成GBDT特征,然后作为LR的特征。这样分成两部分是为了防止过拟合。
X_train, X_train_lr, y_train, y_train_lr = train_test_split(X_train, y_train, test_size=0.5)
# 调用GBDT分类模型。
grd = GradientBoostingClassifier(n_estimators=n_estimator)
# 调用one-hot编码。
grd_enc = OneHotEncoder()
# 调用LR分类模型。
grd_lm = LogisticRegression()
#使用X_train训练GBDT模型,后面用此模型构造特征
grd.fit(X_train, y_train)
# fit one-hot编码器
grd_enc.fit(grd.apply(X_train)[:, :, 0])
#使用训练好的GBDT模型构建特征,然后将特征经过one-hot编码作为新的特征输入到LR模型训练。
grd_lm.fit(grd_enc.transform(grd.apply(X_train_lr)[:, :, 0]), y_train_lr)
# 用训练好的LR模型多X_test做预测
y_pred_grd_lm = grd_lm.predict_proba(grd_enc.transform(grd.apply(X_test)[:, :, 0]))[:, 1]
# 根据预测结果输出
fpr_grd_lm, tpr_grd_lm, _ = roc_curve(y_test, y_pred_grd_lm)
特征搜索
搜索的算法大致可分为完全搜索(Complete),启发式搜索(Heuristic),随机搜索(Random) 3大类。
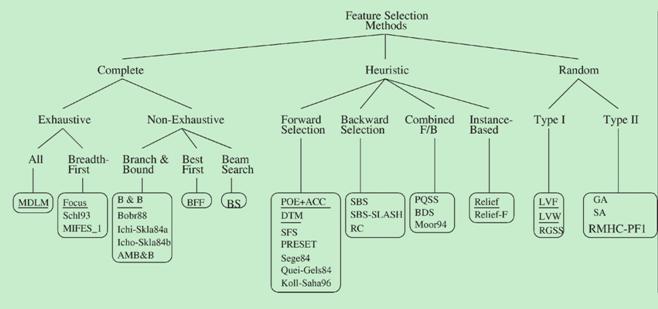
下面对常见的搜索算法进行简单介绍。
- 完全搜索(Complete)
- 广度优先搜索( Breadth First Search ) 广度优先遍历特征子空间。枚举所有组合,穷举搜索,实用性不高。
- 分支限界搜索( Branch and Bound ) 穷举基础上加入分支限界。例如:剪掉某些不可能搜索出比当前最优解更优的分支。 其他,如定向搜索 (Beam Search ),最优优先搜索 ( Best First Search )等
- 启发式搜索(Heuristic)
- 序列前向选择( SFS , Sequential Forward Selection ) 从空集开始,每次加入一个选最优。
- 序列后向选择( SBS , Sequential Backward Selection ) 从全集开始,每次减少一个选最优。
- 增L去R选择算法 ( LRS , Plus-L Minus-R Selection ) 从空集开始,每次加入L个,减去R个,选最优(L>R)或者从全集开始,每次减去R个,增加L个,选最优(L<R)。
其他如双向搜索( BDS , Bidirectional Search ),序列浮动选择( Sequential Floating Selection )等
- 随机搜索(Random)
- 随机产生序列选择算法(RGSS, Random Generation plus Sequential Selection) 随机产生一个特征子集,然后在该子集上执行SFS与SBS算法。
- 模拟退火算法( SA, Simulated Annealing ) 以一定的概率来接受一个比当前解要差的解,而且这个概率随着时间推移逐渐降低
- 遗传算法( GA, Genetic Algorithms ) 通过交叉、突变等操作繁殖出下一代特征子集,并且评分越高的特征子集被选中参加繁殖的概率越高。
随机算法共同缺点:依赖随机因素,有实验结果难重现。
交叉特征
将两列或多列的数据进行处理之后计算内积得到新的特征。以下是交叉特征在CTR中的例子。
在CTR问题中,交叉特征可以被认为是用户特征与广告特征的非线性组合生成的新特征,不同的广告特征跟用户特征可以交叉出不同效果。这样做可以避免部分用户特征无法被使用上的问题。
构造过程:
1.将特征离散化,使用one-hot编码,假设得到n维向量f_user
2.统计不同的item在新生成的N维向量上的分布情况得另一n维向量f_item
3.f_user与f_item计算内积或笛卡尔乘积,作为新生成的交叉特征
例子:
构造人们购买汽车的倾向的特征。
1.假设人分为{穷人,中产,富人},将他们的特征离散化:穷人->(1,0,0),中产 ->(0,1,0),富人 ->(0,0,1)。
2.有三款汽车{奇瑞QQ,camry,宾利},统计购买汽车的三类人的比例,如购买奇瑞QQ的比例为[0.8,0.19,0.01],购买camry的阶层比例为[0.2,0.6,0.2],购买宾利的阶层比例为 [0,0.05,0.95]
3.来了一个属中产特征的人(0,1,0),则可以计算他买三种车的倾向分别为
奇瑞QQ: [0,1,0] dot [0.8,0.19,0.01]=0.19 camry: [0,1,0] dot [0.2,0.6,0.2]=0.6 宾利: [0,1,0] dot [0.,0.05,0.95]=0.05
参考资料
8.小波变换教程
9.离散小波变换
10.维基百科-近似熵
11.维基百科-样本熵
12.时间序列的复杂度和熵