线性特征降维——MF
MF(SVD,ALS)
MF(矩阵分解)包括 奇异值分解(SVD)和交替最小二乘法(ALS)
SVD
SVD理论基础
PCA的实现一般有两种,一种是用特征值分解去实现的,一种是用奇异值分解去实现的。特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个学生,每个学生有M科成绩,这样形成的一个N M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解(SVD)是一个能适用于任意的矩阵的一种分解的方法: 假设A是一个N M的矩阵,那么得到的U是一个N N的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个N M的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),V’(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片
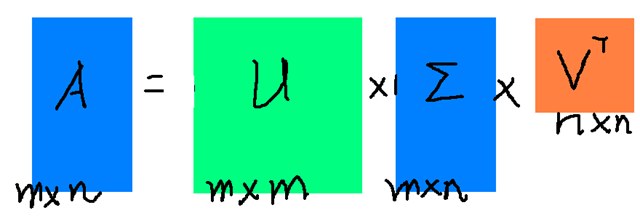
那么现在我们就需要确定左奇异向量和右奇异向量。$ A* A^T $会得到一个方阵,我们对这个方阵进行特征分解: 由此可以求出特征值和特征向量,这个步骤中求出的特征向量就是右奇异向量,特征值为右奇异值,此外我们可以得到
这就是左奇异值和左奇异向量。
奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解: 其中r是一个远远小于n的数,这样矩阵的乘法看起来像是下面的样子:
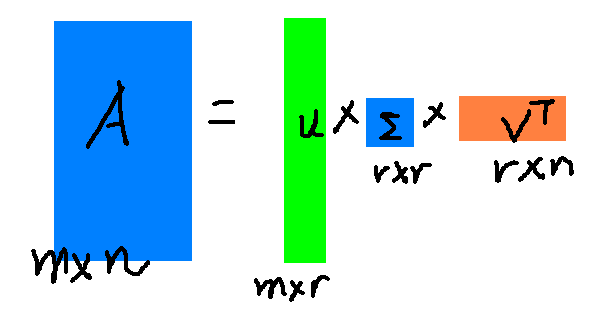
这样就起到了降维的效果。
SVD的python实现
from numpy import linalg as la
import numpy
A = [[1, 2, 3],[4, 5, 6]]
U, sigma, VT = la.svd(A)
ALS
ALS基本原理
ALS的矩阵分解算法常应用于推荐系统中,将用户(user)对商品(item)的评分矩阵,分解为用户对商品隐含特征的偏好矩阵,和商品在隐含特征上的映射矩阵。与传统的矩阵分解SVD方法来分解矩阵R()不同的是,ALS(alternating least squares)希望找到两个低维矩阵,以 来逼近矩阵R,其中 ,,,d 表示降维后的维度,一般 d<<r,r表示矩阵 R 的秩,。
目标函数:
为了找到低维矩阵X,Y最大程度地逼近矩分矩阵R,最小化下面的平方误差损失函数。
为防止过拟合给公式 (1) 加上正则项,公式改下为:
其中,,,是正则项的系数。
模型求解:
固定Y,对 求导 ,得到求解的公式
同理固定X,可得到求解的公式
其中,,,I表示一个d * d的单位矩阵。
基于公式(3)、(4),首先随机初始化矩阵X,然后利用公式(3)更新Y,接着用公式(4)更新X,直到计算出的RMSE(均方根误差)值收敛或迭代次数足够多而结束迭代为止。
其中,,
ALS-WR模型:
以上模型适用于用户对商品的有明确的评分矩阵的场景,然而很多情况下用户没有明确的反馈对商品的偏好,而是通过一些行为隐式的反馈。比如对商品的购买次数、对电视节目收看的次数或者时长,这时我们可以推测次数越多,看得时间越长,用户的偏好程度越高,但是对于没有购买或者收看的节目,可能是由于用户不知道有该商品,或者没有途径获取该商品,我们不能确定的推测用户不喜欢该商品。ALS-WR通过置信度的权重来解决此问题,对于我们更确信用户偏好的项赋予较大的权重,对于没有反馈的项,赋予较小的权重。模型如下:
ALS-WR目标函数
其中
,是置信度系数。
通过最小二乘法求解
其中是一个维的对角矩阵,; 其中是一个维的对角矩阵,。
与其他矩阵分解算法的比较:
- 在实际应用中,由于待分解的矩阵常常是非常稀疏的,与SVD相比,ALS能有效的解决过拟合问题。
- 基于ALS的矩阵分解的协同过滤算法的可扩展性也优于SVD。
- 与随机梯度下降的求解方式相比,一般情况下随机梯度下降比ALS速度快;但有两种情况ALS更优于随机梯度下降:1)当系统能够并行化时,ALS的扩展性优于随机梯度下降法。2)ALS-WR能够有效的处理用户对商品的隐式反馈的数据。
ALS的python实现
import numpy
def mf_als(R, P, Q, K, steps=5000, alpha=0.0002, beta=0.02):
Q = Q.T
for step in xrange(steps):
for i in xrange(len(P)):
e = 0
for i in xrange(len(R)):
for j in xrange(len(R[i])):
if R[i][j] > 0:
e = e + pow(R[i][j] - numpy.dot(P[i,:],Q[:,j]), 2)
for k in xrange(K):
e = e + (beta/2) * (pow(P[i][k],2) + pow(Q[k][j],2))
if e < 0.001:
break
return P, Q.T
if __name__ == "__main__":
R = [
[5,3,0,1],
[4,0,0,1],
[1,1,0,5],
[1,0,0,4],
[0,1,5,4],
]
R = numpy.array(R)
N, M, K = len(R), len(R[0]), 2
P = numpy.random.rand(N,K)
Q = numpy.random.rand(M,K)
nP, nQ = mf_als(R, P, Q, K)
print numpy.dot(nP, nQ.T)
参考资料
- 特征哈希(Feature Hashing)
- Trevor Hastie et al. The Elements of Statistical Learning, 2001.
- Kilian Weinberger et al. Feature Hashing for Large Scale Multitask Learning, 2010.
- Joshua Attenberg et al. Collaborative Email-Spam Filtering with the Hashing-Trick, 2009.
- https://www.zhihu.com/question/264165760/answer/277634591
- sklearn.feature_extraction.FeatureHasher
- sklearn学习笔记2 Feature_extraction库
- 特征选择和稀疏学习
- 《西瓜书》笔记11:特征选择与稀疏表示(三)
- 特征选择与稀疏学习
- https://www.zhihu.com/question/24124122/answer/50403932
- https://blog.csdn.net/u014595019/article/details/52433754
- PCA算法详解
- 主成分分析(PCA)原理详解
- 主成分分析PCA算法:为什么去均值以后的高维矩阵乘以其协方差矩阵的特征向量矩阵就是“投影”?
- 用Python的sklearn库进行PCA(主成分分析)
- 用scikit-learn学习主成分分析(PCA)
- 独立成分分析(Independent Component Analysis)
- 独立成分分析 ( ICA ) 与主成分分析 ( PCA ) 的区别在哪里?
- 独立成分分析ICA系列4:ICA的最优估计方法综述
- ICA-独立成分分析
- 独立成分分析Independent component analysis(ICA)
- 线性判别分析LDA原理总结
- 一文读懂特征工程
- 线性判别分析LDA详解
- LinearDiscriminantAnalysis
- 用scikit-learn进行LDA降维
- https://blog.csdn.net/u010705209/article/details/53518772
- https://blog.csdn.net/u012162613/article/details/42214205
- https://blog.csdn.net/qianhen123/article/details/40077873
- https://github.com/ceys/jdml/wiki/ALS
- 美团点评技术团队之深入FFM原理与实践
- [深度学习笔记(一)稀疏自编码器] (https://blog.csdn.net/u010278305/article/details/46881443)
- Field-aware Factorization Machines for CTR Prediction ,Yuchin Juan et al.
- Factorization Machines, Steffen Rendle et al.[2010]
- http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
- 局部线性嵌入(LLE)原理总结
- Locally linear embedding(LLE)局部线性嵌入-降维
- LocallyLinearEmbedding
- 用scikit-learn研究局部线性嵌入(LLE)
- 聚类和降维的区别与联系
- 聚类算法
- 受限玻尔兹曼机(RBM)学习笔记
- 受限制玻尔兹曼机RBM原理简介
- 从SNE到t-SNE
- t-SNE完整笔记
- SNE降维与可视化
- 比PCA降维更高级 —— t-SNE聚类算法实现指南