非线性特征降维——神经网络
神经网络
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是神经网络的一种,它可应用与降维中。以下会对其作简要介绍。
受限玻尔兹曼机是一种可用随机神经网络(stochastic neural network)来解释的概率图模型(probabilistic graphical model)。RBM是Smolensky于1986年在波尔兹曼机(Boltzmann Machine,BM)基础上提出的,所谓“随机”是指网络中的神经元是随机神经元,输出状态只有两种(未激活和激活),状态的具体取值根据概率统计法则来决定。RBM理论是Hinton在2006年提出基于RBM的(Deep Belief Network)模型,大量学者开始研究RBM的理论及其应用。
RBM的网络结构
RBM包含两个层,可见层(visible layer)和隐藏层(hidden layer)。神经元之间的连接具有如下特点:层内无连接,层间全连接,显然RBM对应的图是一个二分图。一般来说,可见层单元用来描述观察数据的一个方面或一个特征,而隐藏层单元的意义一般来说并不明确,可以看作特征提取层。而当隐层单元比可见层单元数少时,我们也可以把这个看作是一个降维的过程。RBM和BM的不同之处在于,BM允许层内神经元之间有连接,而RBM则要求层内神经元之间没有连接,因此RBM的性质:当给定可见层神经元的状态时,各隐藏层神经元的激活条件独立;反之当给定隐藏层神经元的状态是,可见层神经元的激活也条件独立。
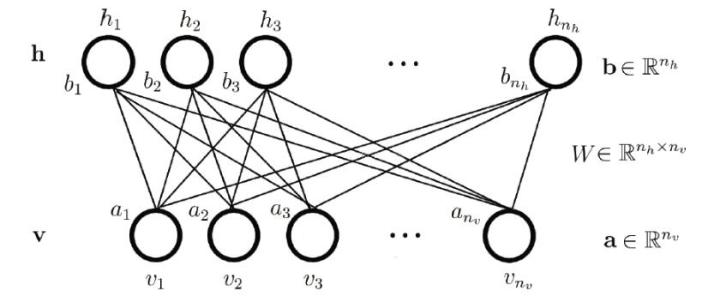
如图给出了一个RBM网络结构示意图。其中:分别表示可见层和隐藏层中包含神经元的数目,下标v,h代表visible和hidden;表示可见层的状态向量;表示隐藏层的状态向量;表示可见层的偏置向量;表示隐藏层的偏置向量;表示隐藏层和可见层之间的权值矩阵,表示隐藏层中第i个神经元与可见层中第j个神经元之间的连接权重。记中的参数,可将其视为把W,a,b中的所有分量拼接起来得到的长向量。
RBM的原理
能量函数和概率分布
RBM模型是基于能量的模型,需要为其定义一个能量函数,并利用能量函数引入一系列相关的概率分布函数。对于一组给定的状态,可定义能量函数:
,
其矩阵向量形式
利用能量函数给出状态的联合概率分布
其中,称作归一化因子,也称作配分函数(Partition Function)。
对于实际问题,我们最关心的是观测数据v的概率分布,对应于的边缘分布,也称作似然函数(likelihood function):。
类似地,我们同样可以得到。对于的计算包含项,其计算复杂度非常高,无法直接计算,需要一些数学推导来简化计算量。
对数似然函数
给定训练样本,RBM的训练意味着调整参数,从而拟合给定的训练样本,使得参数条件下对应RBM表示的概率分布尽可能符合训练数据。
假定训练样本集合为,其中为训练样本的数目,,它们是独立同分布的,则训练RBM的目标就是最大化如下似然,一般通过对数转化为连加的形式,其等价形式:
。
简洁起见,将简记为。
梯度计算
最大化常用的数值方法是梯度上升法(Gradient Ascent),通过迭代的方法进行逼近,迭代形式:,其中表示学习速率。其关键就是计算梯度(关于各个参数的偏导数,,)。
一般采用MCMC采样来估计,但由于常规的MCMC需要经过许多步的状态转移才能保证采集到的样本符合目标分布。若我们以训练样本作为起点,就可以仅需要很少次的状态转移抵达RBM的分布。Hinton教授2002年基于这个上想法发明了对比散度(Contrastive Divergence,CD)算法,目前已经成为训练RBM的标准算法。
参考资料
- 特征哈希(Feature Hashing)
- Trevor Hastie et al. The Elements of Statistical Learning, 2001.
- Kilian Weinberger et al. Feature Hashing for Large Scale Multitask Learning, 2010.
- Joshua Attenberg et al. Collaborative Email-Spam Filtering with the Hashing-Trick, 2009.
- https://www.zhihu.com/question/264165760/answer/277634591
- sklearn.feature_extraction.FeatureHasher
- sklearn学习笔记2 Feature_extraction库
- 特征选择和稀疏学习
- 《西瓜书》笔记11:特征选择与稀疏表示(三)
- 特征选择与稀疏学习
- https://www.zhihu.com/question/24124122/answer/50403932
- https://blog.csdn.net/u014595019/article/details/52433754
- PCA算法详解
- 主成分分析(PCA)原理详解
- 主成分分析PCA算法:为什么去均值以后的高维矩阵乘以其协方差矩阵的特征向量矩阵就是“投影”?
- 用Python的sklearn库进行PCA(主成分分析)
- 用scikit-learn学习主成分分析(PCA)
- 独立成分分析(Independent Component Analysis)
- 独立成分分析 ( ICA ) 与主成分分析 ( PCA ) 的区别在哪里?
- 独立成分分析ICA系列4:ICA的最优估计方法综述
- ICA-独立成分分析
- 独立成分分析Independent component analysis(ICA)
- 线性判别分析LDA原理总结
- 一文读懂特征工程
- 线性判别分析LDA详解
- LinearDiscriminantAnalysis
- 用scikit-learn进行LDA降维
- https://blog.csdn.net/u010705209/article/details/53518772
- https://blog.csdn.net/u012162613/article/details/42214205
- https://blog.csdn.net/qianhen123/article/details/40077873
- https://github.com/ceys/jdml/wiki/ALS
- 美团点评技术团队之深入FFM原理与实践
- [深度学习笔记(一)稀疏自编码器] (https://blog.csdn.net/u010278305/article/details/46881443)
- Field-aware Factorization Machines for CTR Prediction ,Yuchin Juan et al.
- Factorization Machines, Steffen Rendle et al.[2010]
- http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
- 局部线性嵌入(LLE)原理总结
- Locally linear embedding(LLE)局部线性嵌入-降维
- LocallyLinearEmbedding
- 用scikit-learn研究局部线性嵌入(LLE)
- 聚类和降维的区别与联系
- 聚类算法
- 受限玻尔兹曼机(RBM)学习笔记
- 受限制玻尔兹曼机RBM原理简介
- 从SNE到t-SNE
- t-SNE完整笔记
- SNE降维与可视化
- 比PCA降维更高级 —— t-SNE聚类算法实现指南