数据整理
去量纲化

使不同规格的数据转换到同一规格,保证特征的每个维度的取值区间一致。去量纲化的目的是加快算法的训练速度,常见的去量纲化方法有:
- 标准化
- 归一化
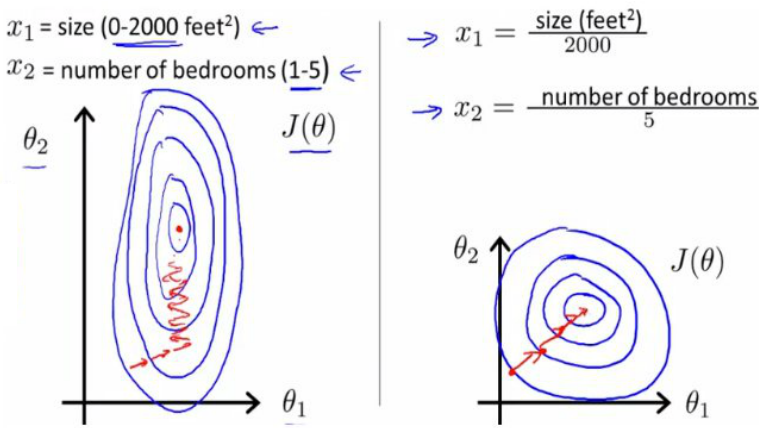
下图是去量纲化的一个示例:蓝色的圈圈代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之”字型路线(垂直等高线走),从而导致需要迭代很多次才能收敛。而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。因此机器学习模型使用梯度下降法求解最优解时,归一化非常有必要,否则很难收敛甚至不能收敛。
有时候归一化也有可能提高精度,比如一些分类器需要计算样本之间的距离,如欧式距离,例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而于实际情况相悖(比如这时的实际情况是值域范围小的特征更重要。)
标准化
标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。Z-score 标准化指的是,通过缩放让数据的均值为0(移除均值),标准差为固定值(比如1)。在许多模型里,如SVM的RBF、线性模型的 L1 & L2 正则项对于所有的feature都有这样的假设。 其中是均值、是标准差。
from sklearn.preprocessing import StandardScaler
#标准化,返回值为标准化后的数据
StandardScaler().fit_transform(iris.data)
举一个实际应用的例子,在对深度学习神经网络的优化中,我们也常常采取一种名为批标准化的策略:
在进行激活函数运算之前加入批标准化的操作,可以促进梯度在网络中的传播,便于设置更高的学习率,从而加快算法的训练速度。
归一化
线性归一化
利用边界值信息,将特征的取值区间缩放到某个特定的范围,例如[0,1]等。
from sklearn.preprocessing import MinMaxScaler
#区间缩放,返回值为缩放到[0, 1]区间的数据
MinMaxScaler().fit_transform(iris.data)
这种归一化方法比较实用在数值比较集中的情况,但是,如果max和min不稳定,很容易使得归一化结果不稳定,后续使用效果也不稳定,实际使用中可以用经验值来代替max和min,而且当有新数据加入时,可能导致max和min的变化,需要重新定义。在不涉及距离度量,协方差计算,数据不符合正态分布的时候,可以使用其他归一化方法。
均值归一化
对数归一化
Sigmoid归一化
对于归一化,因为不同的特征有不同的取值范围,在有些算法中,例如线性模型或者距离相关的模型像聚类模型、knn模型等,特征的取值范围会对最终的结果产生较大影响,例如二元特征的取值范围为[0,1],而距离特征取值可能是[0,正无穷),在实际使用中会对距离进行截断,例如[0,3000000],但是这两个特征由于取值范围不一致导致了模型可能会更偏向于取值范围较大的特征,为了平衡取值范围不一致的特征,需要对特征进行归一化处理,将特征取值归一化到[0,1]区间。
常用的归一化方法包括:
1)函数归一化,通过映射函数将特征取值映射到[0,1]区间,例如最大最小值归一化方法,是一种线性的映射。还有通过非线性函数的映射,例如log函数等。
2)分维度归一化,可以使用最大最小归一化方法,但是最大最小值选取的是所属类别的最大最小值,即使用的是局部最大最小值,不是全局的最大最小值。
3)排序归一化,不管原来的特征取值是什么样的,将特征按大小排序,根据特征所对应的序给予一个新的值。
规范数值变量的原因是不同的特征可能会有不同的数值尺度和单位,举一个我最近碰到的情况为例,在文本分类中,我们常常用tf-idf来判断文章中出现的词语的重要性,并作为分类器的输入特征,每个单词的tf-idf值越大代表该单词的重要性越高,其值一般情况下都很小,仅采用tf-idf和逻辑回归模型进行分类的时候损失值比较低,但是当我加上内容长度、内容中各个不良词语出现个数的时候,损失值有了明显的飙升。我意识到这是因为新加入的特征和与tf-idf值的尺度差别太大,例如文本长度可能在1至数万之间。在这种情况下,标准化就很有必要了,常用的标准化方法有除以最大值、(原数据-极小值)/(极大值-极小值),新数据=1/(1+e^(-原数据)) 等等。需要注意的是,不是所有的特征都需要标准化,像经纬度这种特征如果经过标准化处理可能会导致有用信息的丢失,另外是否需要进行标准化也需要结合使用的机器学习模型来考虑,例如SVM,LR,K-means这些模型标准化能够提升性能,而XGBoost这种树提升模型则不需要进行数值型特征的标准化。
标准化和归一化的区别
简单来说,标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下。归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。规则为l2的归一化公式如下:
from sklearn.preprocessing import Normalizer
#归一化,返回值为归一化后的数据
Normalizer().fit_transform(iris.data)
对定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下: 使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
from sklearn.preprocessing import Binarizer
#二值化,阈值设置为3,返回值为二值化后的数据
Binarizer(threshold=3).fit_transform(iris.data)
数据不平衡问题
抽样平衡
随机采样
抽取任意数目的样本或比例的样本
iris.sample(n=100) #抽取100条数据
iris.sample(frac=0.3) #抽取30%的数据
按权重列采样
在这种采样方式下,用户指定权重列和数据条数 / 采样比例。指定 replace 参数为 True 可启用放回采样。
iris.sample(n=100, weights='sepal_length')
iris.sample(n=100, weights='sepal_length',replace = true)
- 分层采样
随机采样会有隐患,因为某次随机采样得到的数据很不均匀,所以一般是根据特征采用分层采样。
例如对于分类问题:选取正例,负例。对于回归问题,需要采集数据。对于采样得到的样本,根据需要,需要设定样本权重。当模型不能使用全部的数据来训练时,需要对数据进行采样,设定一定的采样率。采样的方法包括随机采样,固定比例采样等方法。
在这种采样方式下,用户指定用于分层的标签列,同时为需要采样的每个标签指定采样比例( frac 参数)或条数 ( n 参数)。暂不支持放回采样
iris.sample(strata='category', n={'Iris Setosa': 10, 'Iris Versicolour': 10})
iris.sample(strata='category', frac={'Iris Setosa': 0.5, 'Iris Versicolour': 0.4})
新增数据
当我们的机器学习算法模型是低偏差的,通过大量数据进行训练我们可以提高预测的精度,但事实情况是,我们拥有的数据不能满足这样的要求。这时候就需要扩充我们的数据库,比较常用的一种方法是人工合成数据。
比如说,我们训练一个模型进行英文字母的识别,但各个字母的训练样本数量不足或者不平衡,我们需要合成模拟数据。在选取一个真实样本后,人为地对样本进行模糊,变形,旋转等操作,生成若干新的样本来获取更多的数据.

对定性特征进行数据变换
连续值->离散化
连续值的取值空间可能是无穷的,为了便于表示和在模型中处理,需要对连续值特征进行离散化处理。常用的离散化方法包括等值划分和等量划分。等值划分是将特征按照值域进行均分,每一段内的取值等同处理。例如某个特征的取值范围为[0,10],我们可以将其划分为10段,[0,1),[1,2),...,[9,10)。等量划分是根据样本总数进行均分,每段等量个样本划分为1段。例如距离特征,取值范围[0,3000000],现在需要切分成10段,如果按照等比例划分的话,会发现绝大部分样本都在第1段中。使用等量划分就会避免这种问题,最终可能的切分是[0,100),[100,300),[300,500),..,[10000,3000000],前面的区间划分比较密,后面的比较稀疏。
离散值->定性特征哑编码
某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。通常使用哑编码的方式将定性特征转换为定量特征:假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果。
由于IRIS数据集的特征皆为定量特征,故使用其目标值进行哑编码(实际上是不需要的)。使用preproccessing库的OneHotEncoder类对数据进行哑编码的代码如下:
from sklearn.preprocessing import OneHotEncoder
#哑编码,对IRIS数据集的目标值,返回值为哑编码后的数据
OneHotEncoder().fit_transform(iris.target.reshape((-1,1)))
扩展 常见的数据变换还有基于多项式的、基于指数函数的、基于对数函数的。
4个特征,度为2的多项式转换公式如下:
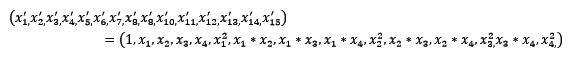
使用preproccessing库的PolynomialFeatures类对数据进行多项式转换的代码如下:
from sklearn.preprocessing import PolynomialFeatures
#多项式转换
#参数degree为度,默认值为2
PolynomialFeatures().fit_transform(iris.data)
基于单变元函数的数据变换可以使用一个统一的方式完成,使用preproccessing库的FunctionTransformer对数据进行对数函数转换的代码如下:
from numpy import log1p
from sklearn.preprocessing import FunctionTransformer
#自定义转换函数为对数函数的数据变换
#第一个参数是单变元函数
FunctionTransformer(log1p).fit_transform(iris.data)
数据合并
Join(merge)
merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False)left与right:两个不同的DataFrame how:指的是合并(连接)的方式有inner(内连接),left(左外连接),right(右外连接),outer(全外连接);默认为inner on : 指的是用于连接的列索引名称。必须存在右右两个DataFrame对象中,如果没有指定且其他参数也未指定则以两个DataFrame的列名交集做为连接键 left_on:左则DataFrame中用作连接键的列名;这个参数中左右列名不相同,但代表的含义相同时非常有用。 right_on:右则DataFrame中用作 连接键的列名 left_index:使用左则DataFrame中的行索引做为连接键 right_index:使用右则DataFrame中的行索引做为连接键 sort:默认为True,将合并的数据进行排序。在大多数情况下设置为False可以提高性能 suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x','_y') copy:默认为True,总是将数据复制到数据结构中;大多数情况下设置为False可以提高性能 indicator:在 0.17.0中还增加了一个显示合并数据中来源情况;如只来自己于左边(left_only)、两者(both)
concat concat函数的基本用法与数据库的union操作相似
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)axis=0 是行拼接,拼接之后行数增加,列数也根据join来定,join=’outer’时,列数是两表并集。同理join=’inner’,列数是两表交集
类型转换
int(x [,base ]) #将x转换为一个整数
long(x [,base ]) #将x转换为一个长整数
float(x ) #将x转换到一个浮点数
complex(real [,imag ]) #创建一个复数
str(x ) #将对象 x 转换为字符串
repr(x ) #将对象 x 转换为表达式字符串
eval(str ) #用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s ) #将序列 s 转换为一个元组
list(s ) #将序列 s 转换为一个列表
chr(x ) #将一个整数转换为一个字符
unichr(x ) #将一个整数转换为Unicode字符
ord(x ) #将一个字符转换为它的整数值
hex(x ) #将一个整数转换为一个十六进制字符串
oct(x ) #将一个整数转换为一个八进制字符串
增加序列号
拆分
分组(group by)一般是指三个过程
- 分割(Splitting)将数据按照某个标准分组
- 应用(Applying)对每个分组分别使用函数
- 组合(Combining)将结果组合成数据框
In [123]: df
Out[123]:
A B C D
0 foo one -0.919854 -1.131345
1 bar one -0.042379 -0.089329
2 foo two 1.247642 0.337863
3 bar three -0.009920 -0.945867
4 foo two 0.290213 -0.932132
5 bar two 0.495767 1.956030
6 foo one 0.362949 0.017587
7 foo three 1.548106 -0.016692
In [124]: grouped = df.groupby('A')
In [125]: grouped['C'].apply(lambda x: x.describe()) # 描述每组信息
Out[125]:
A
bar count 3.000000
mean 0.147823
std 0.301765
min -0.042379
25% -0.026149
50% -0.009920
75% 0.242924
...
foo mean 0.505811
std 0.966450
min -0.919854
25% 0.290213
50% 0.362949
75% 1.247642
max 1.548106
Name: C, dtype: float64
数值型特征向类别特征的转化
有一些连续的数值型特征离散化处理后可以获得更好的效果,比如人的BMI值可以分成过轻、正常、超重、肥胖四个类别。通常可以按照分位点进行类别化处,为不同分段的特征采取不同的分类器,可能可以构建更具体、更准确、更具有针对性的模型。另外,分类型变量可能会有多个级别,比如邮政编码、商品编号中包含了很多层级,处理这种多层级的类别特征可能导致分类器的鲁棒性降低,因此在处理的时候要注意减少类别特征中的层级。在《Subscribe to Data Informed Enhance Machine Learning with Standardizing, Binning, Reducing》(http://data-informed.com/enhance-machine-learning-with-standardizing-binning-reducing/ ) 中,作者举了一个具体的例子,用户的位置总共有20个城市,但是95%的用户来自6个城市,那么我们可以把剩下的5%归纳到一个“other”中而不是一一列举,此外还可以引入“州”来替代用户来自的具体城市,这样减少了特征的维度,可以起到方便可视化、避免过拟合的效果。
在处理类别特征的时候,还有一些其他技巧,比如引入哑变量。考虑这样一个情况,用户使用的操作系统有IOS, Android, Windows,如果我们用一个变量 来表示这个特征的话,x=0和x=2尽管在数值上相差2,但是实际上并没有这种数值联系,仅仅代表这两个用户分别使用了IOS和Windows而已,但模型在处理时无法解释这种情况,因此,我们可以用两个变量和来表示用户使用的操作系统这一特征,n个类别的特征可以用n-1个哑变量来表示,这样增强了特征的解释性。
将非正态分布转化成正态分布
数据正态化,目的是稳定方差,直线化,使数据分布正态或者接近正态。如果y = f(x) 是x的线性函数,不影响分析;但是如果是非线性函数,y和x的表现就完全不同,包括分布,方差和数据间关系也会不同。 比较常见的数据正态化方法包括取对数、取平方根、和取倒数。Box-Cox变换是一种很有效的数据正态化方法,变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。 Box-Cox的公式如下: 其中为样本点的值,y为变换后的值,我们只要确定合适的值就可以应用Box-Cox变换进行数据的正态化处理。那么我们如何来确定一个合适的λ值呢? 我们将转化后的数据当做新的样本集合,计算特征值的平均值和方差,以此可以建立一个正态分布函数(我们假设转换后的样本集合符合正态分布),这样一来我们就可以计算每个样本点出现的概率了,通过最大似然法则,找到最合适的λ值。
KV<->Table
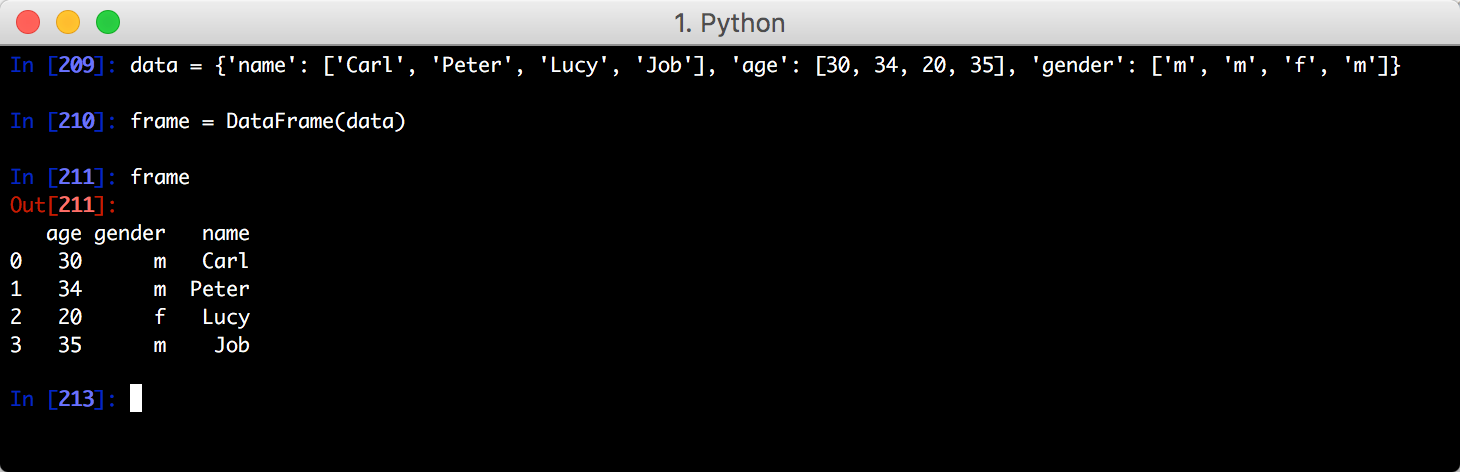
- 字典转DataFrame DataFrame 是一个pandas中表格型的数据结构。它提供有序的列和不同类型的列值
import pandas as pd
from pandas import DataFrame
- DataFrame转字典
import pandas as pd
from pandas import DataFrame
df = pd.DataFrame({'name':[1,2,3],"class":[11,22,33],"price":[111,222,333]})
df.to_dict(orient="dict")
{'class': {0: 11, 1: 22, 2: 33}, 'name': {0: 1, 1: 2, 2: 3}, 'price': {0: 111, 1: 222, 2: 333}}
参考资料
1.https://blog.csdn.net/qq_39303465/article/details/79221254
2.https://wenku.baidu.com/view/baa6346043323968011c92a7.html
3.http://www.cnblogs.com/fengfenggirl/p/iForest.html
4.https://zr9558.com/2016/06/13/outlierdetectionone/
5.https://www.applysquare.com/topic-cn/ShiBHw1ny/
6.https://www.jianshu.com/p/5af3c66e0410?utm_campaign=maleskine
7.http://pyodps.readthedocs.io/zh_CN/latest/df-sort-distinct-apply-zh.html
8.https://blog.csdn.net/zutsoft/article/details/51498026