Chapter 01 特征工程系统
Outlines
- 特征使用方案
- 特征获取方案
- 特征监控方案
- 参考资料
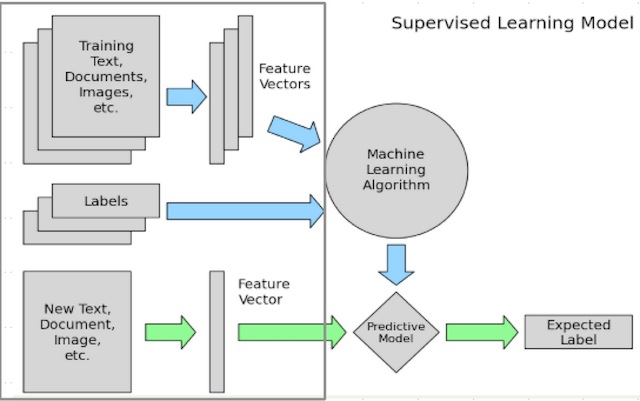
如上图所示是一个经典的机器学习问题框架图。数据清洗和特征挖掘的工作是在灰色框中框出的部分,即“数据清洗=>特征,标注数据生成=>模型学习=>模型应用”中的前两个步骤。 灰色框中蓝色箭头对应的是离线处理部分。主要工作是
- 从原始数据,如文本、图像或者应用数据中清洗出特征数据和标注数据。
- 对清洗出的特征和标注数据进行处理,例如样本采样,样本调权,异常点去除,特征归一化处理,特征变化,特征组合等过程。最终生成的数据主要是供模型训练使用。
灰色框中绿色箭头对应的是在线处理的部分。所做的主要工作和离线处理的类似,主要的区别在于1.不需要清洗标注数据,只需要处理得到特征数据,在线模型使用特征数据预测出样本可能的标签。2.最终生成数据的用处,最终生成的数据主要用于模型的预测,而不是训练。
在离线的处理部分,可以进行较多的实验和迭代,尝试不同的样本采样、样本权重、特征处理方法、特征组合方法等,最终得到一个最优的方法,在离线评估得到好的结果后,最终将确定的方案在线上使用。 另外,由于在线和离线环境不同,存储数据、获取数据的方法存在较大的差异。例如离线数据获取可以将数据存储在Hadoop,批量地进行分析处理等操作,并且容忍一定的失败。而在线服务获取数据需要稳定、延时小等,可以将数据建入索引、存入KV存储系统等。
以美团点击下单率预测为例,结合实例来介绍一个完整的特征工程系统。首先介绍下点击下单率预测任务,其业务目标是提高团购用户的用户体验,帮助用户更快更好地找到自己想买的单子。这个概念或者说目标看起来比较虚,我们需要将其转换成一个技术目标,便于度量和实现。最终确定的技术目标是点击下单率预估,去预测用户点击或者购买团购单的概率。我们将预测出来点击或者下单率高的单子排在前面,预测的越准确,用户在排序靠前的单子点击、下单的就越多,省去了用户反复翻页的开销,很快就能找到自己想要的单子。离线我们用常用的衡量排序结果的AUC指标,在线的我们通过ABTest来测试算法对下单率、用户转化率等指标的影响。