模型仓库
机器学习模型设计五要素 https://zhuanlan.zhihu.com/p/27783413
从ctr预估问题看看f(x)设计—LR篇 https://zhuanlan.zhihu.com/p/27795652
从ctr预估问题看看f(x)设计—DNN篇 https://zhuanlan.zhihu.com/p/28202287
基于深度学习的ctr预估模型集合 https://daiwk.github.io/posts/dl-dl-ctr-models.html
点击率预估模型,如果包括各个模型的变种,可能不下数十种,主流模型大概分几个流派:
- 复杂特征+简单模型:以大规模离散LR为代表,学到的知识全部存储到模型
- 简单特征+复杂模型:以GBDT,DNN为代表,学到的知识存储在特征和模型两个地方
不管哪一种都是就相对静态的,都是截取过去某一个时间片的规律来预测未来。潜在假设是过去时规律在未来同样有效,这种假设在现实面前还是too young too simple,sometimes naive。用户的行为影响推荐系统,推荐系统又反过来影响用户的行为,循环往复;除了这种模型自身的扰动,还有运营手段以及外部大环境的干扰,很多因素都在改变数据中的规律,模型刚上线效果非常好,运行一段时间之后慢慢变得不起作用。目前看到两条路尝试解决这个问题:
- 一条路是“与时俱进”,更快的模型更新直到在线学习
- 另一条路是引入博弈论,强化学习对用户-系统交互行为进行建模
综上,ctr预估的f(x)可以分四个分支。
- 大规模离散LR,
- Trees,
- DNN&Embedding,
- Reinforcement-Learing
沿着大规模离散LR分支的两条演进路线,来看看LR/FM/FFM/CGL/MLR/LASER之间的关系:
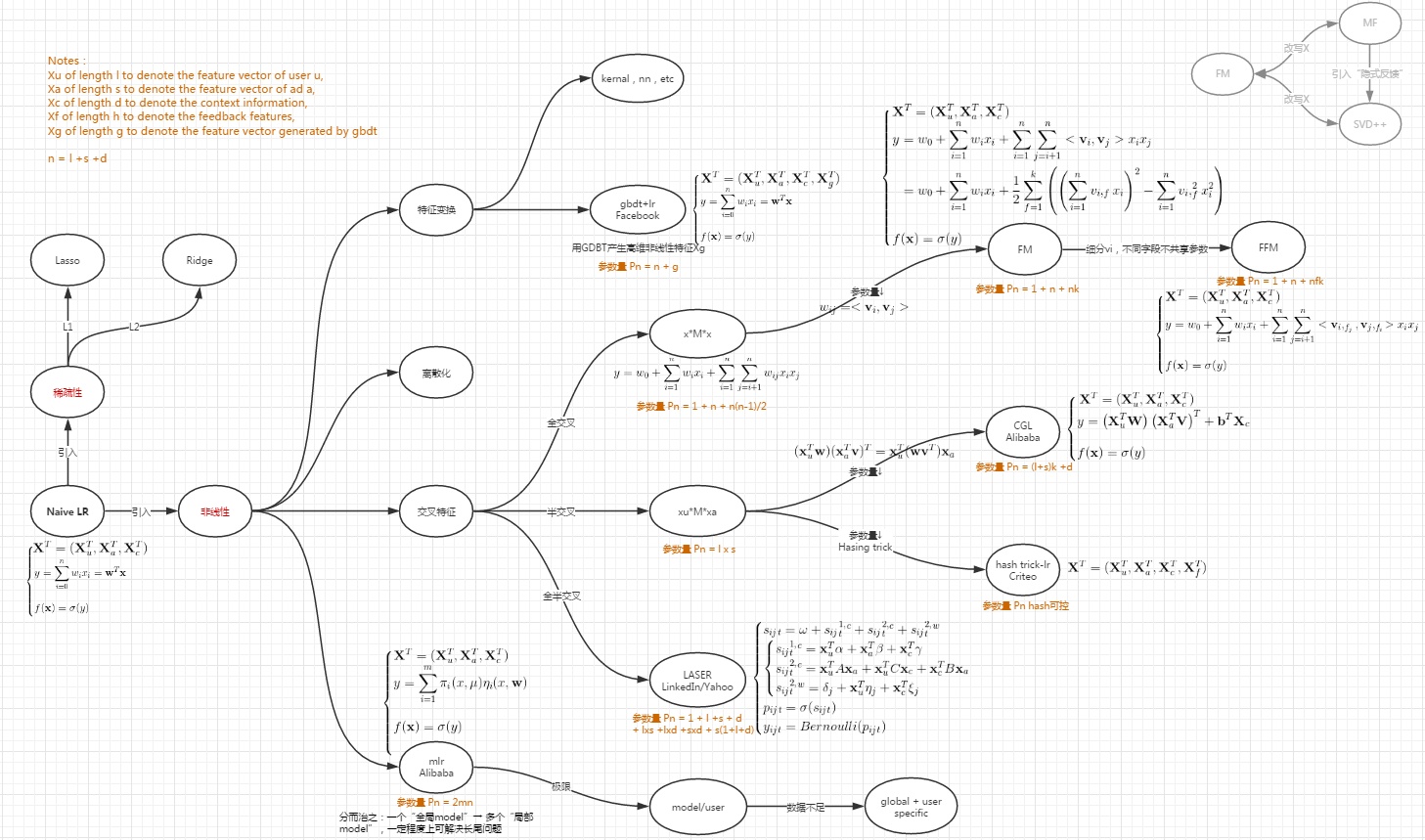
- FM/FFM
- CGL
- LASER
- MLR
DNN&Embedding这条分支的演进路线,把DNN引入ctr预估无非看重两点:
#1 改进模型结构,提高“信息利用率”,发现高阶非线性特征,挖掘以前挖不到潜在模式,比如DIN引入attention机制;一般来说Embedding+MLP是标配。
#2 扩充“信息量”,把图片/文本这类不好处理的数据利用起来,比如DeepCTR;
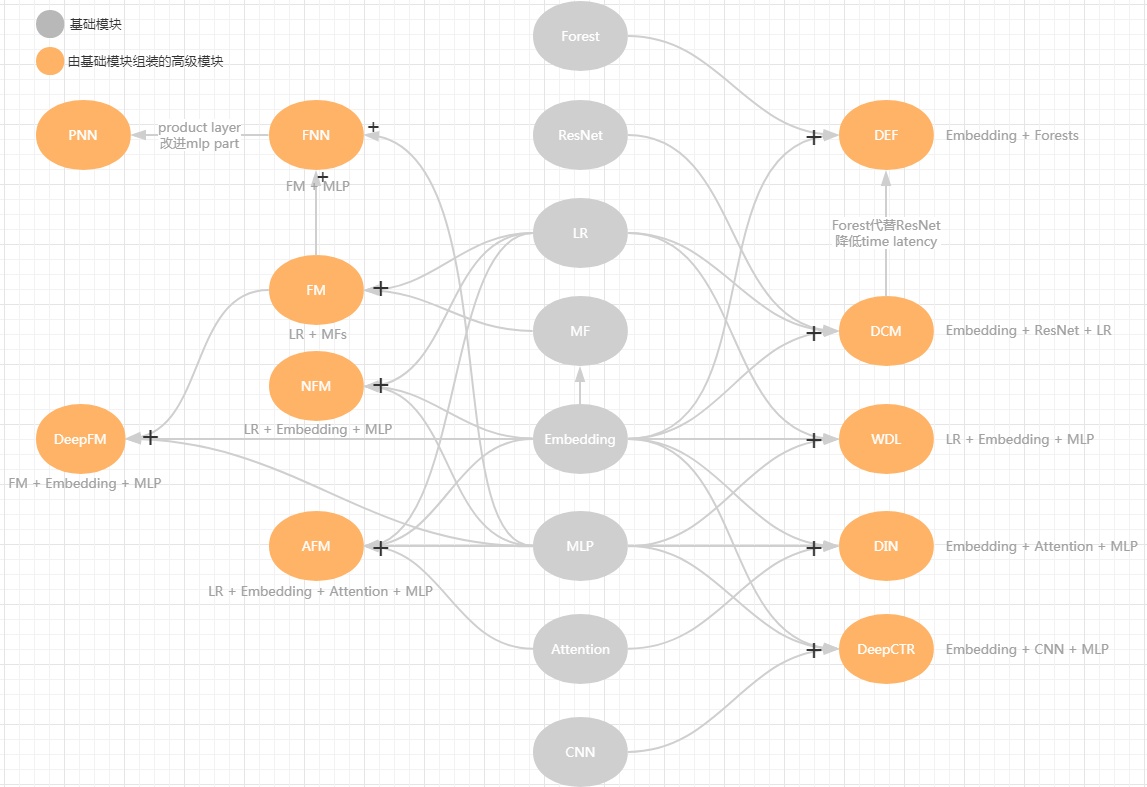
进一步细分为三条演进路线:
#1串行路线 - embedding如何与deep part融合?
- concatenate: wide&deep/DEF/DCM/DeepFM/etc
- inner/outer product: PNN
- weighted sum: DIN/AFM
- Bi-interaction: NFM/AFM
#2并行路线 - shallow part + deep part,结合Memorization 和Generalization的优势,另外通过shallow part把反馈信号传回embedding层,收敛得更快。
- wide&deep:lr + mlp
- DeepFM:fm + mlp
- deep&cross:polynomial cross network + mlp
#3多模学习 - 数字/文本/图片/语音/视频等多形态数据利用起来
-DeepCTR:数字+图片
参考文献
Learning to Rank